メインPCを新調しました
GPT-4による要約
このブログ記事では、著者が2013年に組んだ自身のデスクトップPCを新調した経験について語っています。旧PCは重いアプリの開発時にフリーズする問題が頻発しており、10年間使用されたHaswell CPUのスペック不足が原因と判断されました。旧PCの構成はIntel Core i5-4570S CPU、AMD Radeon RX 570 GPU、24GB DDR3メモリで、UnixBenchベンチマークのスコアはシングルスレッドで1300.1、マルチスレッドで3345.1でした。新しいPCはIntel Core i5 13400F CPU、64GB DDR4メモリを搭載し、UnixBenchのスコアはシングルスレッドで2526.8、マルチスレッドで12092.6と大幅に向上しました。このアップグレードにより著者はパフォーマンスの大幅な向上を実感し、次のアップデートは約10年後になると予測しています。
はじめに
今メインで使用しているデスクトップPCは2013年頃に組んだものです。 電源、マザーボード、GPUなどは交換をしたのですが、CPUは10年前から現役で動いています。
当時はそこそこ新しかったHaswellも、現代の基準では低スペックの方に分類される少し時代遅れな代物になってしまいました。 それでも、まだ十分戦えていたのでこれまでは使用を続けてきました。
しかし、最近それなりに動作の重いアプリを開発する機会があったときPCがフリーズして操作できなくなる現象が多発しました。 topコマンドでシステムパフォーマンスを監視してみたところ、CPUの使用率が100%に張り付いていたため、おそらくHaswellのスペック不足が原因だと思います。
重いアプリを開発するときに毎回フリーズしては困るので、Haswellを卒業することにしました。 ただ、重いアプリ開発や重いゲームをするなどの特殊用途以外ではHaswellは今でもまだまだ戦えると思っています。
これまでの構成とベンチマーク
以下のような構成でした。
| パーツ | メーカー | 型番 | 備考 |
|---|---|---|---|
| CPU | Intel | Core i5-4570S | 4コア4スレッド |
| GPU | AMD | Radeon RX 570 | |
| マザーボード | ASUS | B85M-G | |
| メモリ | シリコンパワー | SP016GBLTU160N22 | DDR3, 24GB |
| 電源 | 玄人志向 | KRPW-AK650W/88+ |
ベンチマークを取得するためにUnix系OS向けのベンチツールである UnixBench を実行しました。 以下が実行結果の一部です。
$ ubench
BYTE UNIX Benchmarks (Version 5.1.3)
System: saber: GNU/Linux
OS: GNU/Linux -- 6.6.7-arch1-1 -- #1 SMP PREEMPT_DYNAMIC Thu, 14 Dec 2023 03:45:42 +0000
Machine: x86_64 (unknown)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
Benchmark Run: 木 1月 04 2024 18:13:25 - 18:41:26
4 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 46855536.1 lps (10.0 s, 7 samples)
Double-Precision Whetstone 7001.5 MWIPS (10.0 s, 7 samples)
Execl Throughput 3514.7 lps (30.0 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 867382.0 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 228200.8 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 2367003.9 KBps (30.0 s, 2 samples)
Pipe Throughput 1481367.1 lps (10.0 s, 7 samples)
Pipe-based Context Switching 137025.4 lps (10.0 s, 7 samples)
Process Creation 7497.5 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 5047.0 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 1464.6 lpm (60.0 s, 2 samples)
System Call Overhead 963172.0 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 46855536.1 4015.0
Double-Precision Whetstone 55.0 7001.5 1273.0
Execl Throughput 43.0 3514.7 817.4
File Copy 1024 bufsize 2000 maxblocks 3960.0 867382.0 2190.4
File Copy 256 bufsize 500 maxblocks 1655.0 228200.8 1378.9
File Copy 4096 bufsize 8000 maxblocks 5800.0 2367003.9 4081.0
Pipe Throughput 12440.0 1481367.1 1190.8
Pipe-based Context Switching 4000.0 137025.4 342.6
Process Creation 126.0 7497.5 595.0
Shell Scripts (1 concurrent) 42.4 5047.0 1190.3
Shell Scripts (8 concurrent) 6.0 1464.6 2441.0
System Call Overhead 15000.0 963172.0 642.1
========
System Benchmarks Index Score 1300.1
Benchmark Run: 木 1月 04 2024 18:41:26 - 19:09:31
4 CPUs in system; running 4 parallel copies of tests
Dhrystone 2 using register variables 151494102.0 lps (10.0 s, 7 samples)
Double-Precision Whetstone 25124.8 MWIPS (10.0 s, 7 samples)
Execl Throughput 11054.3 lps (29.8 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 1526590.9 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 408266.0 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 4463460.4 KBps (30.0 s, 2 samples)
Pipe Throughput 5146668.1 lps (10.0 s, 7 samples)
Pipe-based Context Switching 633179.4 lps (10.0 s, 7 samples)
Process Creation 25656.5 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 10750.4 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 1470.0 lpm (60.1 s, 2 samples)
System Call Overhead 3186426.2 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 151494102.0 12981.5
Double-Precision Whetstone 55.0 25124.8 4568.2
Execl Throughput 43.0 11054.3 2570.8
File Copy 1024 bufsize 2000 maxblocks 3960.0 1526590.9 3855.0
File Copy 256 bufsize 500 maxblocks 1655.0 408266.0 2466.9
File Copy 4096 bufsize 8000 maxblocks 5800.0 4463460.4 7695.6
Pipe Throughput 12440.0 5146668.1 4137.2
Pipe-based Context Switching 4000.0 633179.4 1582.9
Process Creation 126.0 25656.5 2036.2
Shell Scripts (1 concurrent) 42.4 10750.4 2535.5
Shell Scripts (8 concurrent) 6.0 1470.0 2450.0
System Call Overhead 15000.0 3186426.2 2124.3
========
System Benchmarks Index Score 3345.1
様々なテストの総合スコアである System Benchmarks Index Score を見ると、一度目のテスト (シングルスレッド) では 1300.1、二度目のテスト (マルチスレッド) では 3345.1 でした。
新PCの構成とベンチマーク
電源やストレージ、GPUはそのままで CPU、マザーボード、メモリを新調しました。 購入したパーツは以下のとおりです。 これまではCPUクーラーはIntelのCPUの付属品を使っていたのですが、冷却性能に不安があったためDEEPCOOLの空冷クーラーを購入しました。
| パーツ | メーカー | 型番 | 備考 |
|---|---|---|---|
| CPU | Intel | Core i5 13400F | 10コア16スレッド |
| マザーボード | MSI | MAG B760M MORTAR WIFI DDR4 | |
| メモリ | CFD | W4U3200CS-16G | DDR4, 64GB |
| CPUクーラー | DEEPCOOL | AK400 WH R-AK400-WHNNMN-G-1 |

以下がUnixBenchの結果です。
$ ubench
Benchmark Run: 木 1月 04 2024 23:46:32 - 00:14:32
16 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 70405931.9 lps (10.0 s, 7 samples)
Double-Precision Whetstone 10915.6 MWIPS (10.0 s, 7 samples)
Execl Throughput 4890.7 lps (30.0 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 1990358.2 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 537060.8 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 4956289.9 KBps (30.0 s, 2 samples)
Pipe Throughput 3848502.2 lps (10.0 s, 7 samples)
Pipe-based Context Switching 310093.9 lps (10.0 s, 7 samples)
Process Creation 12308.0 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 5881.5 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 3036.8 lpm (60.0 s, 2 samples)
System Call Overhead 3254496.3 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 70405931.9 6033.1
Double-Precision Whetstone 55.0 10915.6 1984.7
Execl Throughput 43.0 4890.7 1137.4
File Copy 1024 bufsize 2000 maxblocks 3960.0 1990358.2 5026.2
File Copy 256 bufsize 500 maxblocks 1655.0 537060.8 3245.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 4956289.9 8545.3
Pipe Throughput 12440.0 3848502.2 3093.7
Pipe-based Context Switching 4000.0 310093.9 775.2
Process Creation 126.0 12308.0 976.8
Shell Scripts (1 concurrent) 42.4 5881.5 1387.2
Shell Scripts (8 concurrent) 6.0 3036.8 5061.3
System Call Overhead 15000.0 3254496.3 2169.7
========
System Benchmarks Index Score 2526.8
------------------------------------------------------------------------
Benchmark Run: 金 1月 05 2024 00:14:32 - 00:42:34
16 CPUs in system; running 16 parallel copies of tests
Dhrystone 2 using register variables 905802663.3 lps (10.0 s, 7 samples)
Double-Precision Whetstone 129262.6 MWIPS (10.0 s, 7 samples)
Execl Throughput 50647.5 lps (30.0 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 1837999.7 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 484469.0 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 5906099.1 KBps (30.0 s, 2 samples)
Pipe Throughput 37963175.0 lps (10.0 s, 7 samples)
Pipe-based Context Switching 3144543.5 lps (10.0 s, 7 samples)
Process Creation 123481.4 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 54089.0 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 7357.9 lpm (60.1 s, 2 samples)
System Call Overhead 13413753.0 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 905802663.3 77618.1
Double-Precision Whetstone 55.0 129262.6 23502.3
Execl Throughput 43.0 50647.5 11778.5
File Copy 1024 bufsize 2000 maxblocks 3960.0 1837999.7 4641.4
File Copy 256 bufsize 500 maxblocks 1655.0 484469.0 2927.3
File Copy 4096 bufsize 8000 maxblocks 5800.0 5906099.1 10182.9
Pipe Throughput 12440.0 37963175.0 30517.0
Pipe-based Context Switching 4000.0 3144543.5 7861.4
Process Creation 126.0 123481.4 9800.1
Shell Scripts (1 concurrent) 42.4 54089.0 12756.8
Shell Scripts (8 concurrent) 6.0 7357.9 12263.2
System Call Overhead 15000.0 13413753.0 8942.5
========
System Benchmarks Index Score 12092.6
System Benchmarks Index Score を見ると、一度目のテスト (シングルスレッド) では 2526.8、二度目のテスト (マルチスレッド) では 12092.6 でした。
| 旧構成 | 新構成 | |
|---|---|---|
| シングルスレッド | 1300.1 | 2526.8 |
| マルチスレッド | 3345.1 | 12092.6 |
シングルスレッドのSystem Benchmarks Index Scoreは 92.2%向上、マルチスレッドでは261.5%向上してました。
おわりに
今回はPCを新調し、新旧のマシンでUnixBenchによるベンチマークを取って性能を比較しました。 ベンチマークの結果、シングルスレッドでは92.2%、マルチスレッドでは261.5%総合スコアが向上していました。
次にまたPCを新調するのは予期せぬ故障がない限りまた10年後とかになるでしょう。 そのときはまたベンチマークをとって性能を比較したいと思います。
VRMをモーション付きでWebブラウザ上で動かしてみる
この記事は whywaita Advent Calendar 2023 12日目の記事です。
前日は id: nersonu さんの「サブスクを整理する」でした。定期的にサブスクの整理をすることは出費を確認する上で大切ですね。
唐突ですが今回は VRM をブラウザ上で描画して Mixamo からダウンロードした fbx ファイルをもとにモーションをつける Web アプリを開発したいと思います。
VRM とは?
VRMは汎用的な3Dのファイル形式であるglTFを拡張した人型3Dアバター向けのファイル形式です。 2018年頃に登場した比較的新しいファイル形式です。
Mixamo とは?
Mixamo は3D CGのモデルやアニメーションを利用できるサービスです。 以下に示すように、複数の3Dアニメーションのモデルなどを利用することができます。

Mixamoでは3Dアニメーションを表現するファイルをFBX形式のファイルでダウンロードすることができます。
成果物
vrm-mixamo-viewer-waita というサービスを作りました。
VRMファイルを画面にドラッグ&ドロップしてボタンを押すとモーション付きでVRMを描画できます。

技術要素
このサービスを開発する上で以下のツールを用いました。
- vite
- react
- three.js
- pixiv/three-vrm
- react-three/fiber
- react-three/drei
詳細について興味のある方は GitHub のコードを見てみてください。
ちなみにUIは glTF Viewer を丸パクリさせてもらいました。
さいごに
今回はMixamoからダウンロードしたfbxファイルをもとにVRMにモーションをつけて描画するサービスを作りました。 VRMにモーションをつけるとなんかいいですね。
Codeforces Problems の不具合対応
概要
Codeforces Problems で特定の問題が大量に表示される不具合が発生しました。 原因はクローラのバグだったので直しました。
はじめに
Codeforces Problems は私が開発した Codefores で出題された問題およびその各ユーザーごとの正答状況を確認しやすくするための Web アプリケーションです.
AtCoder Problems を模倣して作りました。
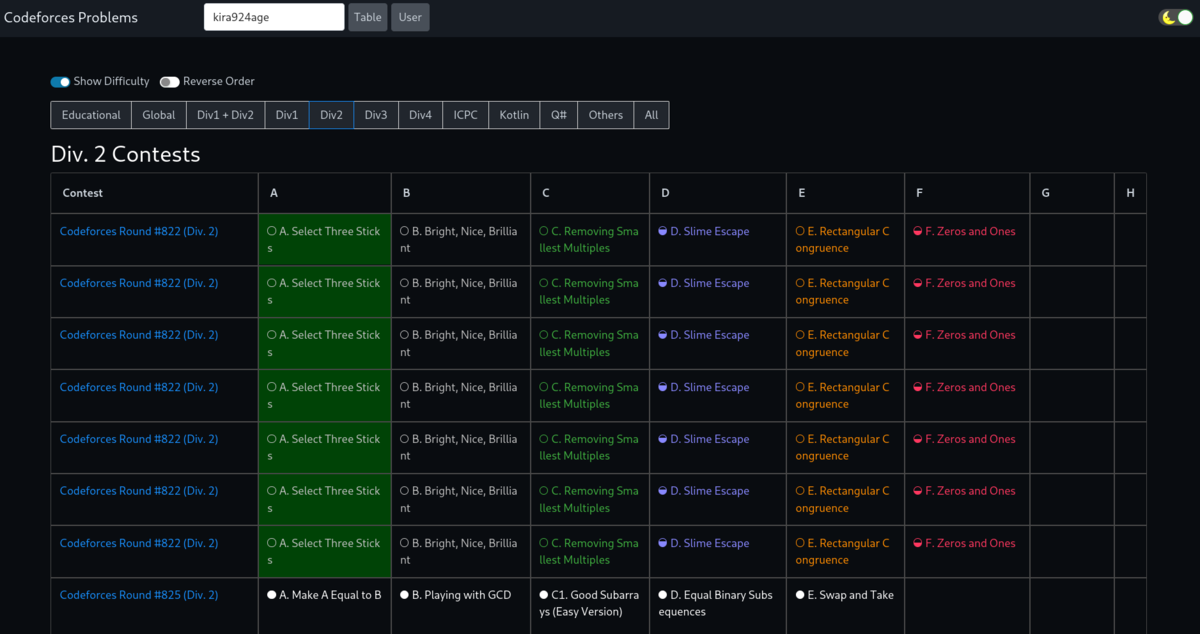
最近 Codeforces Round #822 (Div. 2) が重複して大量に表示されるという不具合が発生しました。
この記事では事象の原因および解決方法について述べます。
発生する事象
以下の画像に示すように同じコンテストが重複して大量に表示されています。
原因の究明
Codeforces Problems では1日1回クローラにより問題のデータを fetch して json ファイルに書き出しています。
コンテストおよび問題のデータが格納されている contests.json を確認したところ、#822 (Div. 2) が重複して格納されていました。
$ cat contests.json | grep 1734 "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, "id": 1734, $ cat contests.json | grep 1734 | wc -l 25
数えてみたら25個同じコンテストの情報が格納されていました。
コンテストの情報の書き込み時の処理を見たところ以下のような Python コードで実装されていました。
if idx != -1: prev_contest = contest_json[idx] if prev_contest["problems"] is None: contest_json[idx] = add elif len(add["problems"]) > len(prev_contest["problems"]): contest_json = [add] + contest_json elif len(add["problems"]) == len(prev_contest["problems"]): for i, (prev_problem, add_problem) in enumerate( zip(prev_contest["problems"], add["problems"])): if prev_problem != None and "rating" in prev_problem: continue contest_json[idx]["problems"][i] = add_problem else: contest_json = [add] + contest_json
idx という変数は更新前のコンテスト情報が格納されているインデックスです。
バグの原因は 1つめ elif ブロックでの記述です。
elif len(add["problems"]) > len(prev_contest["problems"]): contest_json = [add] + contest_json
同じコンテストの情報に関して新しいものと古いものを比較して、新しいほうが古いものより問題数が多かった場合、古い情報とは別にデータを追加しています。
これにより、#822 が無限に書き込まれていました。何を意図したコードなのかは不明です。
以下のコミットによりこのバグを修正しました。
また重複して書き込まれた情報については手で直しました。
終わりに
久しぶりにこのアプリのコードを読んだのですが、今回関連するコードだけ見てもかなりひどかったので近いうちにリファクタリングしたいと思います。
長らく放置している issues の対応もそのうちします。
今回の作業は着手してから記事の執筆も含めて1時間程度で終わったので隙間時間を使ってこれからもちょいちょい手直ししていきたいと思います。
Linux でマイクの入力音量が勝手に下がる問題
概要
Linux で有線接続のマイクの入力音声のボリュームが勝手に下がる現象が発生しました.
これは Zoom や Google Chrome といったクライアントが勝手にデバイスの音量を操作することが原因であることが分かりました。
また Pulse Audio 側でクライアントによる音量操作を無効化するオプションは現時点では用意されていないようでした。
そこで以下のようなスクリプトを常時実行するという手法によりデバイス音量を一定に保つことでクライントによる音量操作を事実上無効化することに成功しました。
(alsa_input.???-?????.analog-stereo はデバイス名で適切に置換する必要があります)
$ while sleep 0.1; do pacmd set-source-volume alsa_input.???-?????.analog-stereo 65535; done
環境
以下のようなソフトウェアを使用している環境で検証しました.
- OS :
Ubuntu 20.04 - デスクトップ環境 :
GNOME 3.36.5 - サウンドサーバー :
pulseaudio 13.99.1 - Zoom :
Version: 5.9.3 (1911)
$ cat /etc/os-release NAME="Ubuntu" VERSION="20.04.3 LTS (Focal Fossa)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 20.04.3 LTS" VERSION_ID="20.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=focal UBUNTU_CODENAME=focal $ gnome-shell --version GNOME Shell 3.36.9 $ pulseaudio --version pulseaudio 13.99.1
事象の再現
Zoom Version: 5.9.3 (1911)
Zoom で会議に参加してマイクを有線接続。ミュートを解除して何かしらの音をマイクに拾わせたところ自動的にマイクの音量が小さくなりました。
音量の設定にはデバイスごとの設定とアプリごとの設定がありますが、今回自動的に下がったのはデバイスごとの設定のみでした。
以下のキャプチャは GNOME のデフォルトのシステム設定を行う GUI である 設定 (Setting) のサウンド設定の画面です。
入力デバイスの音量が自動的に下がっていることが確認できます。(もちろん音量を手動で下げているわけではありません)

Google Chrome (Google Meet)
この問題は Zoom 固有の問題ではなく他のアプリケーションでも発生しました。
Google Chrome 上で Google Meet を起動し会議に参加してマイクに音声を拾わせた場合も同様の事象が発生しました。

原因
ググったら同様の事象についての質問が既にありました。
どうやら Zoom や Google Chrome といったクライアントアプリ側で自動で入力デバイスの音量を調節するという迷惑な機能があるようです。
Zoom の場合は以下のように Automaticcaly adjast microphone volume という設定項目があり, クライアント側でこの機能をオフにすることができました。

実際にこの機能をオフにした状態で Zoom で会議に参加してマイクに音を拾わせたところ自動的に音量が変化する現象はなくなりました。
しかし, Google Chrome で Google Meet のようなアプリを起動している場合はアプリ側でこの機能をオフにすることはできなさそうでした。
以下に引用するように, Google Chrome ではおそらく WebRTC プロトコルが使われており, Chrome/Chromium の WebRTC 実装には Auto Gain Control という機能があり,
ウェブアプリ自体にこの機能をオフにするオプションが無い限りオフにできないらしいです。
Unfortunately the WebRTC implementation in Chromium comes with a handy “feature” called Automatic Gain Control that tends to screw with your microphone volume. Unless the web app itself gives you an option to disable it, there is otherwise no way turn it off, and Chrome developers don't want to add a global “off switch” for it.
また, PulseAudio 側でクライアントによる音量操作を無効化するオプションは現時点では用意されていないようでした。issue がたっていました。
- 関連する issues
解決策
下記の質問の解答の内最も upvote が多いものを試したところクライアント側で入力デバイスの音量を変更を事実上禁止することができました。
手法は単純で以下のスクリプトを実行するだけです。
$ while sleep 0.1; do pacmd set-source-volume alsa_input.???-?????.analog-stereo 65535; done
なお, alsa_input.???-?????.analog-stereo のところは下記のコマンドで得られるデバイス名で適切に置換する必要があります。
$ pacmd list-sources | grep alsa_input
name: <alsa_input.usb-USB_HD_Camera_USB_HD_Camera-02.iec958-stereo>
name: <alsa_input.pci-0000_00_1b.0.analog-stereo>
name: <alsa_input.usb-USB_HD_Camera_USB_HD_Camera-02.iec958-stereo.echo-cancel>
私の場合は alsa_input.pci-0000_00_1b.0.analog-stereo で置換しました。
このスクリプトは 0.1 秒ごとに pacmd という PulseAudio の設定を変更するコマンドを実行してデバイスの音量を固定値としています。
65535 という値は 100% に該当します。上記の質問の解答者は 90000 (135%) に設定していました。
この手法は無駄に CPU リソースを使うのであまりエレガントな解決法とは呼べなさそうです。
しかし残念ながら現時点ではクライアントからデバイスの音量の制御を抑制する方法としてはこれくらいしかなさそうです。
今後 PulseAudio に新しいオプションが追加されることを期待したいです。(お前がコミットしろ)
このスクリプトを実行すると以下のように手動でデバイス音量を調節しようとしても固定値にすぐに戻されてしまいます。 バグっぽいですがこれは意図した通りの挙動です。

毎回このスクリプトを手動で実行するのは面倒なので, systemd により起動時に自動で実行するようにしてみます。
上記のシェルスクリプトを適当な場所に保存して chmod +x で実行権限を付与します。
次に、以下のように ~/.local/share/systemd/user/ に systemd ファイルを作成します。
ExecStart に渡す PATH は絶対PATHで指定しました。
$ vim ~/.local/share/systemd/user/no-agc.service $ cat ~/.local/share/systemd/user/no-agc.service [Unit] After=pulseaudio.service Requires=pulseaudio.service [Service] ExecStart=/home/kira924age/work/configs/saber/pulse-audio/no-agc.sh ExecReload=/bin/kill -s HUP $MAINPID KillSignal=SIGQUIT TimeoutStopSec=5 KillMode=process PrivateTmp=true Restart=always [Install] WantedBy=default.target
次に以下のコマンドで自動起動を有効にします。
$ systemctl --user enable no-agc.service
再起動して service が起動していれば勝ちです。
$ sudo reboot
$ systemctl --user status no-agc.service
● no-agc.service
Loaded: loaded (/home/kira924age/.local/share/systemd/user/no-agc.service;>
Active: active (running) since Thu 2022-02-17 22:06:44 JST; 13s ago
Main PID: 2141 (no-agc.sh)
CGroup: /user.slice/user-1000.slice/user@1000.service/no-agc.service
├─2141 /bin/bash /home/kira924age/work/configs/saber/pulse-audio/n>
└─4359 sleep 0.1
2月 17 22:06:44 saber systemd[2083]: Started no-agc.service.
2月 17 22:06:46 saber no-agc.sh[2190]: デーモンが応答しません
試したけどうまく行かなかった手法
ArchWiki の以下の項目に書いてあることも試しましたがうまく動作しませんでした。
/usr/share/pulseaudio/alsa-mixer/paths/analog-input*.confに該当するファイルを検索. (Ubuntu の場合は Arch とは該当ファイルがあるディレクトリが異なっていました)
$ sudo ls /usr/share/pulseaudio/alsa-mixer/paths/ | grep -oE ^analog-input.*\.conf$ analog-input-aux.conf analog-input-dock-mic.conf analog-input-fm.conf analog-input-front-mic.conf analog-input-headphone-mic.conf analog-input-headset-mic.conf analog-input-internal-mic-always.conf analog-input-internal-mic.conf analog-input-linein.conf analog-input-mic-line.conf analog-input-mic.conf analog-input-rear-mic.conf analog-input-tvtuner.conf analog-input-video.conf analog-input.conf
検索に該当した全てのファイルについて以下のようにファイルを編集 (!!! PulseAudio の設定ファイルを編集する前にバックアップを取ることをおすすめします。何かあったときにすぐ元に戻せるようにしたほう良さそうです !!!)
[Element Capture]の下の volume を zero に設定[Element Internal Mic Boost]の下の volume を zero に設定[Element Int Mic Boost]の下の volume を zero に設定[Element Mic Boost]の下の volume を zero に設定
(注意) [Element Headphone Mic Boost] や [Element Mic Boost (+20dB)] といった全てのバリエーションでも同様に設定する
PulseAudio を再起動して設定を反映させる。
$ pulseaudio -k $ pulseaudio --start
この手法は PulseAudio の Auto Gain Cntorol を無効化する方法としていろいろなところで紹介されているものですが私の場合はうまく動作しませんでした。
音量が小さくなる現象はなくなりましたが、逆に大きくなる現象が発生しました。
また, /usr/share/pulseaudio/alsa-mixer/paths/ は PulseAudio のパッケージを更新するたびに上書きされるので, そのたびに編集する必要があります。
参考文献
AtCoder Problems のパクリアプリ CF Problems を作りました
概要
AtCoder Problems を模倣して CF Problems という Web Application を作りました.
(2021-07-07追記) 衝突を避けるためにサイト名を Codeforces Problems に改名しました.
はじめに
AtCoder Problems の Codeforces 版みたいな Web Application があったら良いなと思っていたのですが, これまでのところ私の観測する範囲では存在していませんでした.
(2021-07-07追記) あとでちゃんと探したらありました.
- Contest Mania
- https://tom0727.github.io/cf-problems/
- このブログ書いた後に出来たサイト
そして, ちょうど Web フロントエンドの勉強をしたいということもあり良い機会だと思って作りました. 下記に示すリンクから作ったものを見ることが出来ます.
Codeforces は Codeforces API という API を公開しているので今回はこれを利用しました.
開発の際は AtCoder Problems と yukicoder problems のコードを参考にさせてもらいました.
宇宙ツイッタラーX (@kenkoooo) さん, iiljj さん, その他のコントリビューターの皆さんに感謝してます.
CF Problems とは?
CF Problems は Codeforces API を利用して Codeforces の問題およびユーザー情報を本家とは違う形で表示するフロントエンドツールです.
AtCoder Problems っぽいものを目指して作りましたが, 実装が面倒あるいは Codeforces API のみでは不可能だった機能を省きました.
まず. ページが Table と User の2種類しかありません. List は面倒だったので省きました. (今後やる気があれば実装するかもしれません)
それぞれのページの外観は以下の画像が示す通りです.
Tableページの外観

Userページの外観

AtCoder Problems に寄せた外観であることが確認できます.
既知の問題点
CF Problems には現時点で把握しているだけでも以下のような問題点があります.
- 本来表示されて欲しい問題が Table ページに表示されないことがある.
例えば直近では Codeforces Round #700 (Div. 2) のC問題以降が Table で表示されていません.
これは Codeforces API の仕様なのでフロントエンド側で対処するのは難しそうです.
なので当分あるいは永遠に改善されないと思います.
(2021-07-07追記) GitHub Actions でクローラを定期実行することでこの問題は解決しました.
issue URL : Div1 と Div2 の併設回で共通で出題されている問題がテーブルページにおいてどちらか一方にしか表示されない · Issue #1 · kira924age/CodeforcesProblems · GitHub
- Dark Theme で Table を Chrome 系のブラウザで表示すると右に謎の白い線が入る
以下の画像に示すとおり謎の白い線が Table に右側に表示されています. CSS を色々いじったのですが消えてくれないです. ちなみに FireFox ではなぜか表示されません. 意味不明です.

(2021-09-12追記) 何もしてないのに今見たら手元の環境では治ってました. ブラウザ (Chrome) のバグだったのかも?
- コードが雑
これは機能的な問題ではないのですが, コードがとても雑です.
Web フロントエンド初心者が雑に書いたものなのでそれはそうです.
具体的に言うと, TypeScript の型定義をサボって any を多用した,
エラーハンドリングをサボった, などがあります.
コードが雑なので把握していないバグが潜んでいる可能性は非常に高いです.
汚いコードは下記の GitHub のリポジトリから見ることが出来ます.
使用したツール
最後にアプリケーションを作る上で利用したツールを書いておきます.
- React
- JavaScript の View ライブラリです
- https://github.com/facebook/react
- Create React App
- ワンライナーで環境構築をしてくれる便利なやつです
- https://github.com/facebook/create-react-app
- ant-design
- 自称世界で2番目に人気のある React UI Library です
- https://github.com/ant-design/ant-design
- recharts
- React 向けのグラフ描画ライブラリです
- https://github.com/recharts/recharts
- nivo
@nivo/calendarを使って Heatmap を実装しました- https://github.com/plouc/nivo
- react-router
- ルーティング (ここでは状態 と URL を紐付けるの意) するために使いました
- https://github.com/ReactTraining/react-router
- react-toggle
- toggle (切り替え) 機能を手軽に実装するために使いました
- https://github.com/aaronshaf/react-toggle
- react-helmet
- theme の切り替え機能を実装するために使いました
- https://github.com/nfl/react-helmet
- react-collapse
- collapse (折りたたみ) 機能を手軽に実装するために使いました
- https://github.com/nkbt/react-collapse
- drawio-desktop
- Codeforces っぽいロゴを作成するのに使いました
- https://github.com/jgraph/drawio-desktop
- Favicon Generator
- Favicon を作成するのに使いました
- https://favicon.io/favicon-generator/
- Codeforces API
- GitHub Pages
- GitHub Actions
- クローラの定期実行やデプロイの自動化をするために使いました.
- Public Repository なら制限無しで無料で使えてお得
- Go